
Football Data Collection (in plain English)
The 4 Ways to Collect Football Data—and the Best Starting Point for Beginners

Hi friend,
Welcome to The Python Football Review #010.
Today we’re tackling the unglamorous but absolutely critical first step in any football analytics project: collecting the data.
By the end of this issue you’ll know the 4 main ways to source football data—and how to start pulling it with only a few lines of Python, all explained in plain English.
Before we get started, just a quick heads-up.
I’ve started working on a beginner-friendly Fast-Track Guide to Football Analytics with Python.
It will be packed with useful templates, practical case studies, and easy-to-follow explanations.
If you’d like to be the first to know when it launches (and maybe even grab an early-bird bonus), you can join the waitlist below:
Okay, so grab a coffee, and let’s dive in.
What Data Collection Really Means
Most coding courses hand you spotless CSVs. Real life doesn’t.
Unless you work somewhere that pipes cleaned match feeds straight to your desk, you are the data engineer. Your job is to move raw numbers—from a website, an API, or a database—onto your machine in a format you can actually use.
Ian Graham, Liverpool’s former Director of Research and the brains behind the first in-house analytics department in the Premier League, recalls sprinting into the office the morning after their 4-0 comeback against Barcelona just to open an analysis-ready match file. Lovely—if you have a dedicated data engineering team.
Most of us don’t.
So here’s how to do it yourself.

1—Manual Copy
Sometimes the fastest route is staring you in the face: open Understat or FBref, copy-paste the table into Excel, job done.
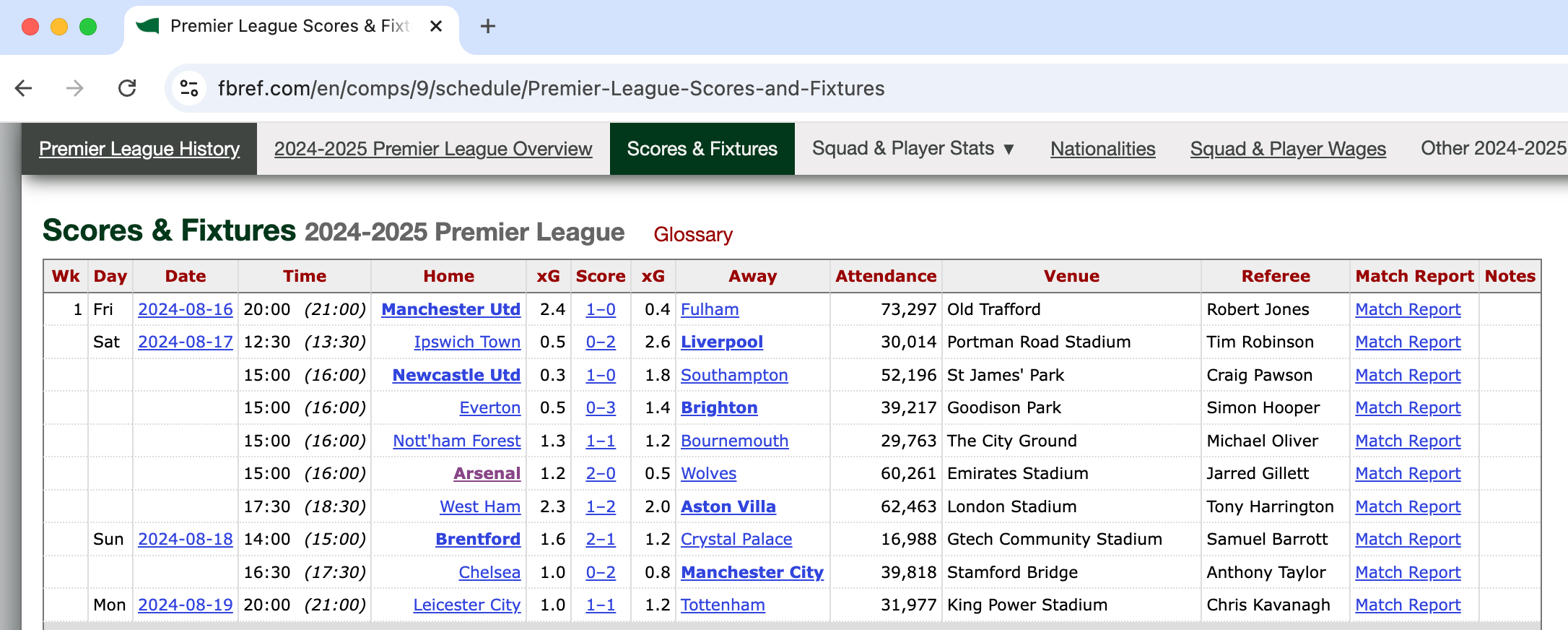
There’s nothing technically tricky here—other than finding exactly what you need.
But manual work can’t be automated, and it doesn’t scale.
Thank you, Captain Obvious.
Still, for a quick sanity check or a one-off chart, copy-paste is quicker than spinning up a full scraper.
You can do even better: never start copying until you’ve checked GitHub or Kaggle.
Chances are someone has already posted the dataset you need. If you can read_csv() or read_html() a clean file in a single line, take the gift and run.
2—Web Scraping
The data you need isn’t always gift-wrapped. It may sit behind dynamic tables, dropdown menus, or JavaScript calls that no public wrapper touches. Web scraping is the art of writing a script that visits a page, finds the right pieces of the markup, and copies the numbers to your machine.
In practice you:
Request the page’s HTML.
Parse its nodes (individual tags such as
<tr>or<td>that hold text).Extract what you need and save it to a DataFrame.
Expect a learning curve though.
You’ll juggle CSS selectors (mini-queries like .table-row > td:nth-child(3) that tell Python “grab the 3rd cell in each row”), deal with cookies and CAPTCHAs, and respect robots.txt so you don’t hammer the host server.
Typical Python toolkit
requests+BeautifulSoupfor quick and clean for static pages and simple tables.Seleniumfor spinning up a headless browser so you can click buttons, open dropdowns, and wait for JavaScript to load.pandas.read_html()– a one-liner that sometimes grabs simple tables without extra code (You can check out McKay Johns’s brilliant explanation on YouTube).
Scraping could fill a course by itself, but even basic skills pay off: once you automate a tricky site, the data updates are yours forever.
Now, if you’d rather skip copy-pasting (too basic, not scalable) and avoid the overhead of building custom scrapers (steep learning curve, time-consuming upkeep), you have two smoother routes:
Pay for polished feeds—exactly what most pro clubs do. Providers like Opta, StatsBomb, or Wyscout deliver match files that are already cleaned and documented.
Lean on community wrappers—open-source libraries that pull multiple seasons of advanced metrics with a single line of Python.
We’ll look at the paid option first, then wrap up with the beginner-friendly community wrappers that most hobby analysts start with.
3—Paid APIs
Professional setups lean on APIs—stable web endpoints that deliver data in a clean, documented format. (API = Application Programming Interface: a contract that lets your code request specific data from a provider’s server.)
Think of it as web-scraping’s legal, high-speed, fully supported cousin—just one that usually comes with a price tag.
Typical workflow
Create an account and grab your personal API key.
Read the docs for the endpoint you need—
/matches,/shots,/players, etc.Hit the URL, pass your key, and pull back a JSON payload (basically one giant nested dictionary you’ll flatten during wrangling).
Pros
Clean, consistent schema—no guessing which table cell holds the xG.
Historical depth and live feeds.
Official support; if something breaks, you have a help desk.
Cons
Cost (sometimes eye-watering).
You still have to wrangle the JSON into tidy columns—just a smaller headache than messy HTML.
Pricing varies. Wyscout is usually cheaper; StatsBomb is the gold-standard and priced accordingly.
If you’re working on a hobby project and don’t need live updates, take advantage of StatsBomb’s free datasets—entire seasons (e.g., Europe’s top-five leagues 2015/16), Arsenal’s 2003/04 Invincibles, Bayer Leverkusen’s 2023/24 unbeaten run, even Lionel Messi’s whole career. Grab them here: https://statsbomb.com/what-we-do/hub/free-data/ or use their Python library statsbombpy.
Ready for the easiest path of all?
Enter community wrappers that fetch those same metrics in a single line of Python.
4—Community wrappers
The football analytics community has blessed us with Python wrappers—packages that hide 97 % of the scraping grunt work.
Instead of copy-pasting from FBref, building a custom crawler, or paying StatsBomb money you don’t have, you can often import a library and fetch the data in a single line.
Flagship wrapper: soccerdata by Pieter Robberechts. Behind the scenes it scrapes several public sources and returns tidy (pandas) DataFrames. With the same package you can tap into
FBref & Understat: xG, xGOT, xA, xGChain, xGFlow, shot locations, and other advanced team/player stats
SofaScore, WhoScored, FotMob: line-ups and player ratings
ClubElo: historical team strength
SoFIFA: FIFA/FC player attributes
…and more (full documentation here).
Usually it’s one line to set parameters, one line to pull clean data. Simple as that.
Why beginners love wrappers
Zero scraping headaches—instant gratification
Perfect sandbox to practise Polars/Pandas before wrestling with raw HTML
Caveats
Community projects can go stale; endpoints change and packages break—be ready to fork or patch
Documentation still matters—read it so you hit the right methods and parameters
Coverage is uneven: plenty of x-metrics for Europe’s top five leagues, far less for lower tiers or niche competitions
Bottom line: start with wrappers. If they cover your use-case, you’re already analysing. If not, fall back on the other three roads: manual copy, web scraping, or APIs.
5—The Python Corner
And finally — here’s the Python code of the day.
It illustrates why starting with wrappers is the fastest and most efficient way for beginners to begin collecting advanced, up-to-date football data.
So, how do you get xG data for Europe’s top five leagues for the past eight seasons?
Easy.
First, install soccerdata (if you haven’t already), and load the library along with a data-wrangling tool — in this case, Polars.

Then, define the scope of your data. You simply call sd.FBref(), set the league to "Big 5 European Leagues Combined", and select the seasons from 2017–18 through the current 2024–25 season. After that, use .read_schedule() — and voilà, the data is yours.
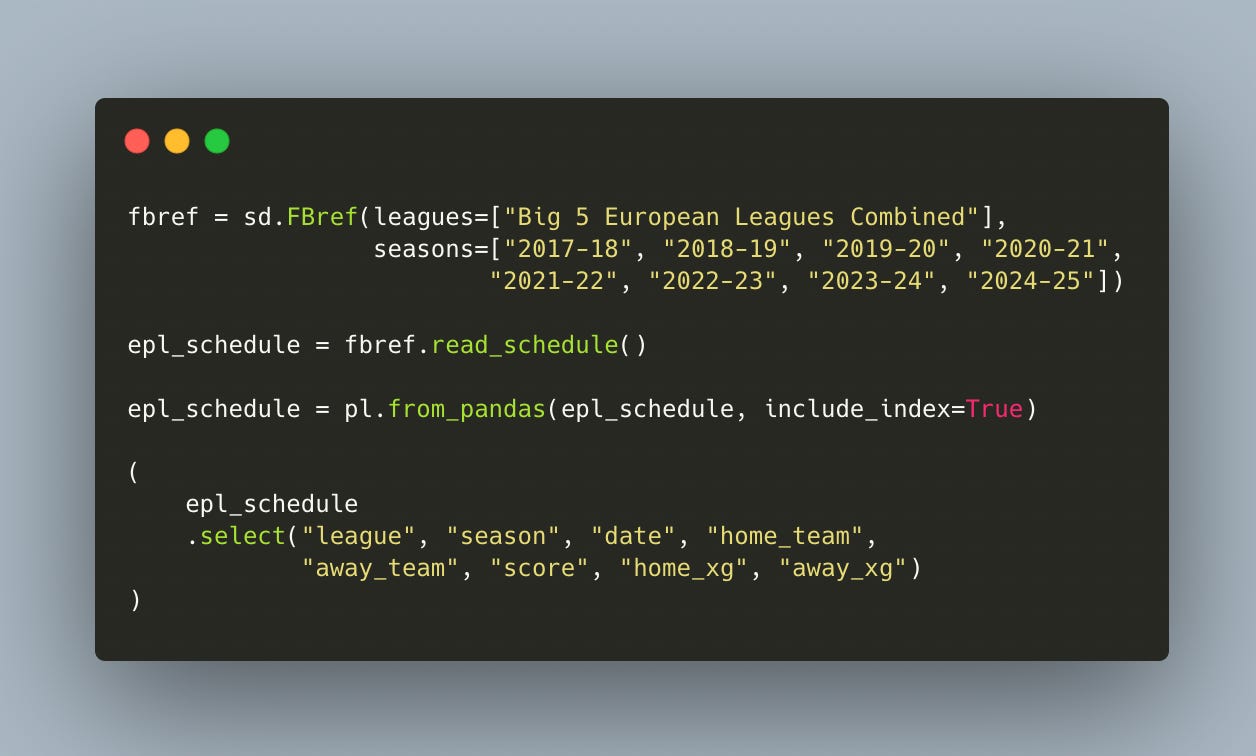
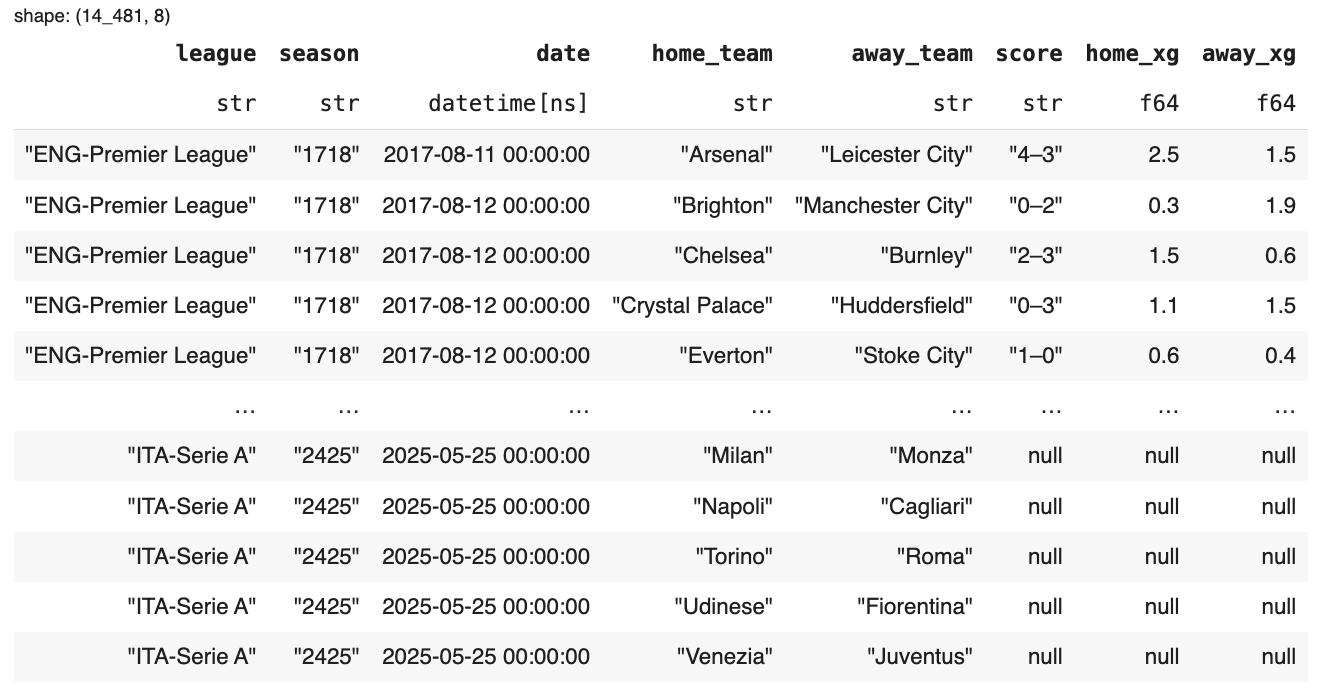
In the code example, we also convert the resulting DataFrame to a Polars DataFrame to take advantage of its friendly, high-performance syntax.
And that’s it — quick and easy, just as promised.
Boom—that was data collection in plain English.
If you found this newsletter helpful, please spread the word! You now know the 4 ways you can get started collecting football data.
I’m still experimenting with the format of the newsletter, so your feedback is super welcome—would you prefer shorter content, longer deep dives, more Python, or more football concepts? Or does this format hit the mark?
My aim is to build a truly practical newsletter together with you.
Until next week,
Martin
The Python Football Review
Unfortunately, nearly all scrapers or scraping methods on FBref.com aren't working anymore (Mar 15th, 2026). Correct me if I'm wrong.
epl_schedule = fbref.read_schedule() returns the ff error: [12/15/25 09:01:24] ERROR Error while scraping https://fbref.com/en/comps/. Retrying... (attempt _common.py:545
1 of 5).
Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py",
line 525, in _download_and_save
response.raise_for_status()
File "/usr/local/lib/python3.12/dist-packages/requests/models.py",
line 1026, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url:
https://fbref.com/en/comps/
[12/15/25 09:01:30] ERROR Error while scraping https://fbref.com/en/comps/. Retrying... (attempt _common.py:545
2 of 5).
Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py",
line 525, in _download_and_save
response.raise_for_status()
File "/usr/local/lib/python3.12/dist-packages/requests/models.py",
line 1026, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url:
https://fbref.com/en/comps/
[12/15/25 09:01:36] ERROR Error while scraping https://fbref.com/en/comps/. Retrying... (attempt _common.py:545
3 of 5).
Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py",
line 525, in _download_and_save
response.raise_for_status()
File "/usr/local/lib/python3.12/dist-packages/requests/models.py",
line 1026, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url:
https://fbref.com/en/comps/
[12/15/25 09:01:42] ERROR Error while scraping https://fbref.com/en/comps/. Retrying... (attempt _common.py:545
4 of 5).
Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py",
line 525, in _download_and_save
response.raise_for_status()
File "/usr/local/lib/python3.12/dist-packages/requests/models.py",
line 1026, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url:
https://fbref.com/en/comps/
[12/15/25 09:01:48] ERROR Error while scraping https://fbref.com/en/comps/. Retrying... (attempt _common.py:545
5 of 5).
Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py",
line 525, in _download_and_save
response.raise_for_status()
File "/usr/local/lib/python3.12/dist-packages/requests/models.py",
line 1026, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url:
https://fbref.com/en/comps/
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
/tmp/ipython-input-2124964271.py in <cell line: 0>()
----> 1 epl_schedule = fbref.read_schedule()
4 frames
/usr/local/lib/python3.12/dist-packages/soccerdata/_common.py in _download_and_save(self, url, filepath, var)
551 continue
552
--> 553 raise ConnectionError(f"Could not download {url}.")
554
555
ConnectionError: Could not download https://fbref.com/en/comps/.
Anyone with a help?